Gradient Boosted Decision Trees and Random Forest are one of the best ML models for tabular heterogeneous datasets.
CatBoost is an algorithm for gradient boosting on decision trees. Developed by Yandex researchers and engineers, it is the successor of the MatrixNet algorithm that is widely used within the company for ranking tasks, forecasting and making recommendations. It is universal and can be applied across a wide range of areas and to a variety of problems.
CatBoost, the new kid on the block, has been around for a little more than a year now, and it is already threatening XGBoost, LightGBM and H2O.
Why CatBoost?
Better Results
Catboost achieves the best results on the benchmark, and that is great.
Though, when you look at datasets where categorical features play a large role, this improvement becomes significant and undeniable.

Faster Predictions
While training time can take up longer than other GBDT implementations, prediction time is 13–16 times faster than the other libraries according to the Yandex benchmark.

Batteries Included
CatBoost’s default parameters are a better starting point than in other GBDT algorithms and it is good news for beginners who want a plug and play model to start experience tree ensembles or Kaggle competitions.

Some more noteworthy advancements by Catboost are the features interactions, object importance and the snapshot support.In addition to classification and regression, Catboost supports ranking out of the box.
Battle Tested
Yandex is relying heavily on Catboost for ranking, forecasting and recommendations. This model is serving more than 70 million users each month.
The Algorithm
Classic Gradient Boosting

CatBoost Secret Sauce
CatBoost introduces two critical algorithmic advances — the implementation of ordered boosting, a permutation-driven alternative to the classic algorithm, and an innovative algorithm for processing categorical features.
Both techniques are using random permutations of the training examples to fight the prediction shift caused by a special kind of target leakage present in all existing implementations of gradient boosting algorithms.
Categorical Feature Handling
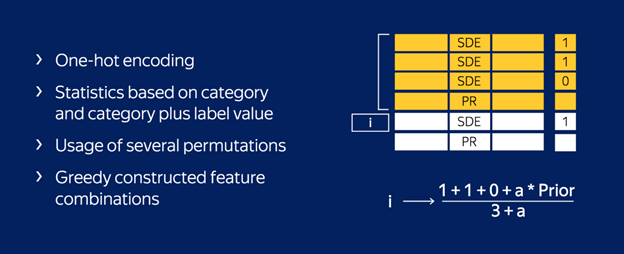
Ordered Target Statistic
Most of the GBDT algorithms and Kaggle competitors are already familiar with the use of Target Statistic (or target mean encoding).
It’s a simple yet effective approach in which we encode each categorical feature with the estimate of the expected target y conditioned by the category.
Well, it turns out that applying this encoding carelessly (average value of y over the training examples with the same category) results in a target leakage.
To fight this prediction shift CatBoost uses a more effective strategy. It relies on the ordering principle and is inspired by online learning algorithms which get training examples sequentially in time. In this setting, the values of TS for each example rely only on the observed history.
To adapt this idea to a standard offline setting, Catboost introduces an artificial “time” — a random permutation σ1 of the training examples.
Then, for each example, it uses all the available “history” to compute its Target Statistic.
Note that, using only one random permutation, results in preceding examples with higher variance in Target Statistic than subsequent ones. To this end, CatBoost uses different permutations for different steps of gradient boosting.
One Hot Encoding
Catboost uses a one-hot encoding for all the features with at most one_hot_max_size unique values. The default value is 2.
Ordered Boosting
CatBoost has two modes for choosing the tree structure, Ordered and Plain. Plain mode corresponds to a combination of the standard GBDT algorithm with an ordered Target Statistic.
In Ordered mode boosting we perform a random permutation of the training examples — σ2, and maintain n different supporting models — M1, . . . , Mn such that the model Mi is trained using only the first i samples in the permutation.
At each step, in order to obtain the residual for j-th sample, we use the model Mj−1.
Unfortunately, this algorithm is not feasible in most practical tasks due to the need of maintaining n different models, which increase the complexity and memory requirements by n times. Catboost implements a modification of this algorithm, on the basis of the gradient boosting algorithm, using one tree structure shared by all the models to be built.

In order to avoid prediction shift, Catboost uses permutations such that σ1 = σ2. This guarantees that the target-yi is not used for training Mi neither for the Target Statistic calculation nor for the gradient estimation.
Tuning Catboost
Important Parameters
cat_features — This parameter is a must in order to leverage Catboost preprocessing of categorical features, if you encode the categorical features yourself and don’t pass the columns indices as cat_features you are missing the essence of Catboost.
one_hot_max_size — As mentioned before, Catboost uses a one-hot encoding for all features with at most one_hot_max_size unique values. In our case, the categorical features have a lot of unique values, so we will not use one hot encoding, but depending on the dataset it may be a good idea to adjust this parameter.
learning_rate & n_estimators — The smaller the learning_rate, the more n_estimators needed to utilize the model. Usually, the approach is to start with a relative high learning_rate, tune other parameters and then decrease the learning_rate while increasing n_estimators.
max_depth — Depth of the base trees, this parameter has a high impact on training time.
subsample — Sample rate of rows, cannot be used in a Bayesian boosting type setting.
colsample_bylevel, colsample_bytree, colsample_bynode— Sample rate of columns.
l2_leaf_reg — L2 regularization coefficient
random_strength — Every split gets a score and random_strength is adding some randomness to the score, it helps to reduce overfitting.

Check out the recommended spaces for tuning here
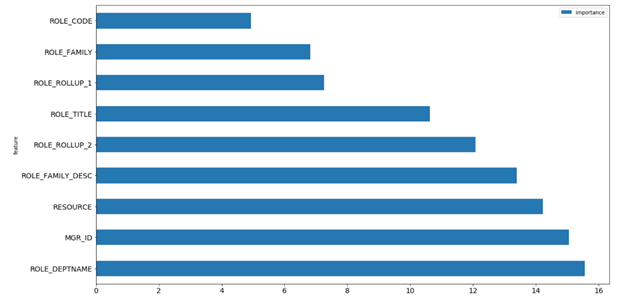
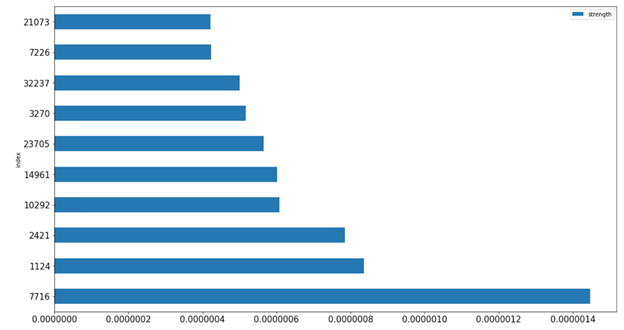
Model Exploration with Catboost
In addition to feature importance, which is quite popular for GBDT models to share, Catboost provides feature interactions and object (row) importance

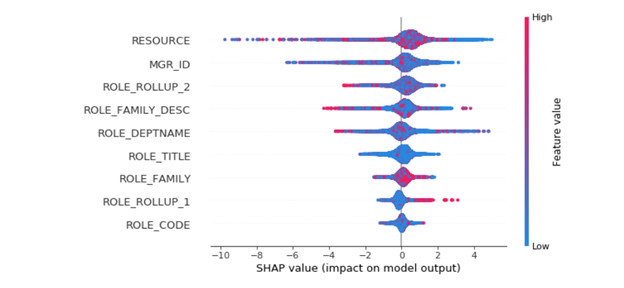
Not only does it build one of the most accurate model on whatever dataset you feed it with — requiring minimal data prep — CatBoost also gives by far the best open source interpretation tools available today AND a way to productionize your model fast.
That is why CatBoost is revolutionising the game of Machine Learning, forever. And that is why learning to use it is a fantastic opportunity to up-skill and remain relevant as a data scientist. But more interestingly, CatBoost poses a threat to the status quo of the data scientist (like me) who enjoys a position where it is supposedly tedious to build a highly accurate model given a dataset. CatBoost is changing that. It is making highly accurate modeling accessible to everyone.

Building highly accurate models at blazing speeds
Installation
Installing CatBoost on the other end is a piece of cake. Just run
pip install catboost
Data prep needed
Unlike most Machine Learning models available today, CatBoost requires minimal data preparation. It handles:
· Missing values for Numeric variables
· Non encoded Categorical variables.
Note missing values have to be filled beforehand for Categorical variables. Common approaches replace NAs with a new category ‘missing’ or with the most frequent category.
· For GPU users only, it does handle Text variables as well.
Unfortunately I could not test this feature as I am working on a laptop with no GPU available. [EDIT: a new upcoming version will handle Text variables on CPU. See comments for more info from the head of CatBoost team.]
Building models
As with XGBoost, you have the familiar sklearn syntax with some additional features specific to CatBoost.
from catboost import CatBoostClassifier # Or CatBoostRegressor
model_cb = CatBoostClassifier()
model_cb.fit(X_train, y_train)
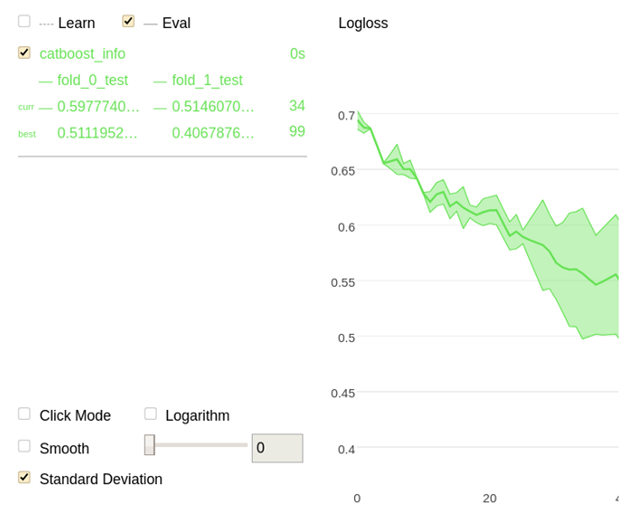
Or if you want a cool sleek visual about how the model learns and whether it starts overfitting, use plot=True and insert your test set in the eval_set parameter:
from catboost import CatBoostClassifier # Or CatBoostRegressor
model_cb = CatBoostClassifier()
model_cb.fit(X_train, y_train, plot=True, eval_set=(X_test, y_test))
Note that you can display multiple metrics at the same time, even more human-friendly metrics like Accuracy or Precision. Supported metrics are listed here. See example below:
Monitoring both Logloss and AUC at training time on both training and test sets
You can even use cross-validation and observe the average & standard deviation of accuracies of your model on the different splits:
Finetuning
CatBoost is quite similar to XGBoost. To fine-tune the model appropriately, first set the early_stopping_rounds to a finite number (like 10 or 50) and start tweaking the model’s parameters.
This Blog is written by Anamika Jha, Business Analyst, Affine.